

ビッグデータ分析で特に重要な「非構造化データ」における「コンピュータービジョン(画像解析)」とは―テクノロジー最前線 データアナリティクス&AI編(9)
2022-12-09
DX(デジタルトランスフォーメーション)の進展とともにデータ利活用の需要が高まる中、組織が保有するデータ群(ビッグデータ)の「量(volume)」と「種類(variety)」の重要性が一層高まっています。
ビッグデータは「構造化データ」と「非構造化データ」に分けられますが、圧倒的にボリュームと種類が多いのが「非構造化データ」です。
顧客データや売上データなど、表形式で整理できる「構造化データ」に対し、画像、動画、音声、文書など、そのままでは定型的に扱えないのが「非構造データ」です。「構造化データ」は扱いやすい一方で、含まれる情報は限定されてしまうため、さまざまな課題を解決するために「非構造化データ」を処理・分析するニーズが高まっています。今回は、その「非構造化データ」の中でも代表的な画像データの処理を可能にする技術「コンピュータービジョン」について解説します。
コンピュータービジョンはデジタル画像や動画をコンピューターが理解できるようにする技術です。この技術はコンピューターが人間と同様に、自動的にデジタル画像を把握し、処理し、分析し、理解できるようになることを目指しており、さらに、既存データをもとに画像を生成できるようにもなっています。しかし、機械はゼロから画像を認識することができるわけではありません。通常、データサイエンティストはアルゴリズムや理論をベースに画像認識のモデルを構築し、作業の種類や目的に合わせて、モデルに学習させる必要があります。
1. コンピュータービジョンはどのようにして機能するのか
コンピュータービジョンのモデルは、作業の目的やアルゴリズムによってさまざまなものがあります。
典型的なモデルの一つは、「畳み込みニューラルネットワーク(Convolutional Neural Network:CNN)」と呼ばれるものです。CNNは画像の特徴を抽出することができます。
例えば、私たちはどうやってある画像が猫であり、犬ではないと見分けているでしょうか?とがった耳と光る眼でしょうか?もちろん猫の画像には犬の画像と違った特徴が他にもいくつもあるはずです。
CNNは、人間が視覚によって画像を認識するのと同様の方法で画像を判別します。画像からその特徴を取り出して(この特徴は人間には理解できないものかもしれません)、それが何の画像であるかを判断するのです。ある特徴が猫のものであり、犬のものではないという判断ができるようにするために、猫か犬かのラベルが付けられた大量の画像をモデルに学習させます。何千回ものトレーニングを行うことでモデルは自動的に猫の画像を判別できるようになります。
一般的に、CNNモデルには2つのフェーズがあります。一つは特徴を抽出するフェーズ(Features extraction)、もう一つは分類のフェーズ(Classification)です(図1)。CNNを含むニューラルネットワークのアルゴリズムでは、インプット(画像を細かいセルに分けて数値化したもの)が多ければ多いほど、大量の計算リソースが必要となります。
図1:CNNモデル

CNNモデルの特徴抽出のフェーズには、通常2タイプの層があります。
1)畳み込み層(Convolutional layers):画像の特徴を抽出
2)プーリング層(Pooling layers):データの容量を縮小
特徴抽出のフェーズでは、
- 畳み込み層でカーネルとの掛け合わせをし、画像データそのままではなく、画像の特徴を特徴マップとして抽出する
- 1で得られた特徴マップをプーリング層でさらに圧縮し、分類フェーズのインプットの数を減らす
という処理が行われます。ニューラルネットワークのインプットの数が少なくなると、必要な計算リソースも減ります。
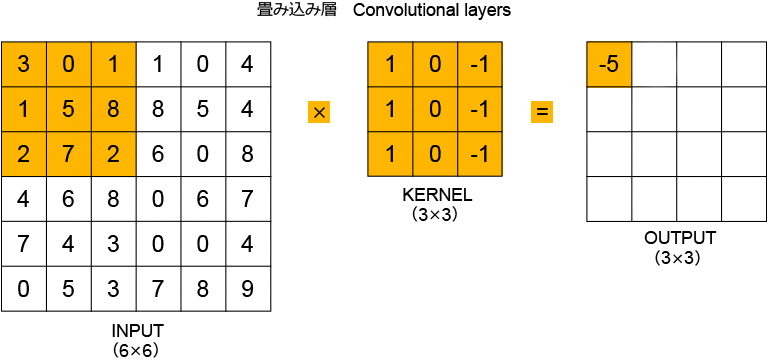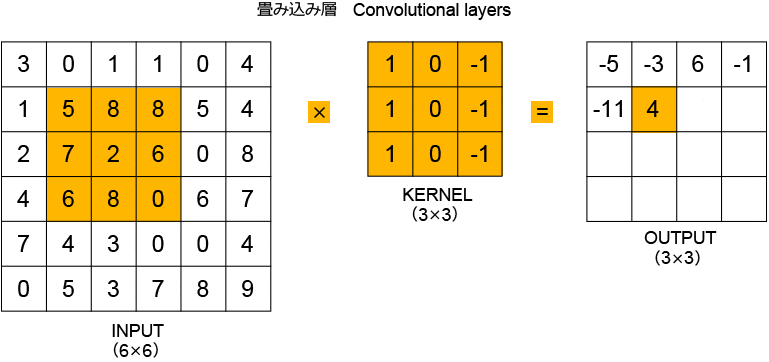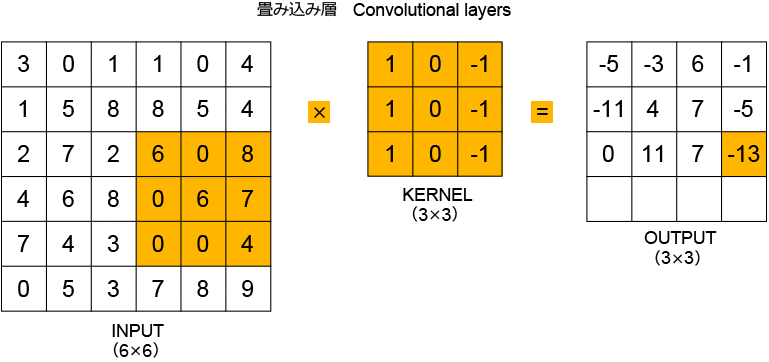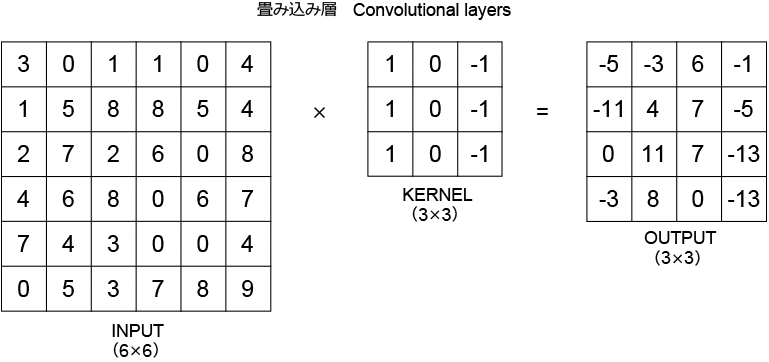
畳み込み層について少し詳しく見ていきます(図2)。畳み込み層では、インプットを「畳み込み演算」し、その結果を次の層に渡します。畳み込み演算には、正方形のカーネルが使われます。上の例では、まず、インプットの左上の3×3のセルにある数値を、3×3のカーネルの同じ位置にある数値と掛け合わせています。この掛け算の結果の総和がアウトプットの左上のマスに表示された「-5」となります。インプットのセルを一つずつずらして掛け算を行うことで、4×4のアウトプット(これは「特徴マップ」と呼ばれます)になります。カーネルの中の数値の初期値は全て「1」ですが、モデルの学習によって数値が決定されます。
図2:畳み込み層の計算プロセス
一方、プーリング層は、畳み込み層で計算した特徴マップを圧縮します。例えば、先ほど生成した4×4の特徴マップを2×2ごとに計算(手法により平均値や最大値を取る)して、新たに2×2ダウンサンプリング画像を生成します。これにより、カーネル形状の位置ずれを吸収することが可能となります。
次に、画像の分類のフェーズにおいては、分類のために全結合層(Fully Connected Layer)が使用されます。全結合層では、プーリング層で縮小された特徴マップのデータをインプットとし(図3のX1、X2)、図3のfの式である「活性化関数」により、特定の分類(図3のY)にどの程度紐づいているかが計算されます。それぞれのインプットがある分類に紐づく確率(w1、w2)はモデルの学習によって決定されます。
図3:全結合層の計算プロセス

モデルを構築する際に、層の数やカーネルの大きさを決定できます。しかしながら、カーネルが大きければ大きいほど、層が深ければ深いほど、より多くの計算リソースが必要になります。
CNNはディープラーニングの一種なので、pyTorchやtensorflowなど、どのディープラーニングのライブラリーでも使用可能なCNNモデルがいくつかあるため、それらのライブラリーを使用し、CNNモデルを作成することもできます。モデルの学習にはかなりの時間を要するため、事前にある程度の学習が済んでおり、必要な学習を追加的に行うだけで使用可能な、リソースを削減できるモデルもあります。
2. コンピュータービジョンの使用例
コンピュータービジョンはさまざまなタスクをこなしています。いくつかご紹介しましょう。
1) 画像分類
画像分類はコンピューターに何の画像かを理解させる技術であり、画像をラベルごとに分類することを目指しています。前節では基本的な画像分類の方法をご紹介しましたが、直近10年間のコンピュータービジョンの発展により、ほとんどの画像データの分類作業において、およそ90%正しく分類できるようになりました。
図4:画像データベースImageNetの画像に対する画像分類において最も精度の高いモデルの推移
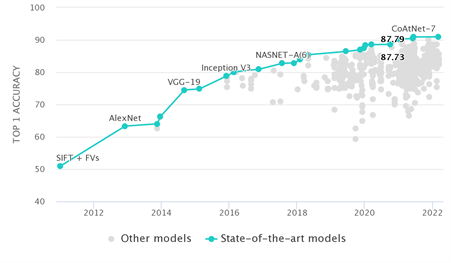
出典:Papers With Code (https://paperswithcode.com/sota/image-classification-on-imagenet)
2) 物体検出
物体検出は、画像の中にある物体が何であるかを検出する技術です。画像を分類する時には、画像を一つのものとして認識しますが、物体を検出する際には、画像の中にある各物体を認識しなければならないため、画像の分類よりかなり難しい技術になります。しかし、最新の物体検出技術を使うと、画像だけでなく、リアルタイム動画でも複数の物体が検出できるようになりました。
図5:物体検出の例

出典:Detectron(https://github.com/facebookresearch/detectron)
3) 画像生成
画像生成は、既存のデータから新しい画像を生成(合成)するものです。例としては、10万点以上の人間の画像を学習し、この世に存在しない人間の画像を生成するモデルがあります。このタイプにはディープフェイク(Deepfake)※に代表される高い不正リスクがあるため、このような最先端の技術が不正に利用されることのないよう、AIを活用した対策も必要になっています。
※深層学習(Deep learning)を用いて、2つ以上の写真や動画の一部を入れ替える技術。「深層学習 (Deep learning)」と「偽物 (Fake)」から派生した言葉。
執筆者

S. Zhang
2018年にPwCアドバイザリー合同会社に入社し、現在はフォレンジックのデータ・アナリティクスチームに所属。データ・エンジニアとして機械学習、ETLおよびデータビジュアライゼーションに関する幅広い知識を有する。
PwC Japanグループでは、データアナリティクス領域でご活躍いただける方を募集しています。本記事に関連する求人情報は以下ページよりご覧ください。
|
テクノロジー最前線―先端技術とエンジニアリングによる社会とビジネスの課題解決に向けて
データアナリティクス&AI編
(1):テック人材の採用と維持における企業の課題
(2):フィーチャーエンジニアリングとは?
(3):SNSを活用したコロナ禍における人々の心理的変化の洞察
(4):自然言語処理(NLP)の基礎
(5):今、データサイエンティストに求められるスキルは何か?データサイエンティスト求人動向分析
(6):コロナ禍における人流および不動産地価変化による実体経済への影響
(7):「匠」の減少―技能継承におけるAI活用の道しるべ
(8):開示された企業情報におけるESGリスクと財務インパクトの関係性の特定
(9):ビッグデータ分析で特に重要な「非構造化データ」における「コンピュータービジョン(画像解析)」とは
(10):自然言語処理・数理最適化による効率的なリスキリングの支援
(11):スポーツアナリティクスの黎明 サッカーにおけるデータ分析
(12):AIを活用した価格設定支援モデルの検討―外部環境変化に即座に対応可能な次世代型プライシング
(13):MLOps実現に向けて抑えるべきポイントー最前線
(14):合成データにより加速するデータ利活用
エマージングテクノロジー編
(1):ブロックチェーン技術の成熟度モデルとステーブルコインの最新動向について
(2):3次元空間情報の研究施設「Technology Laboratory」のデジタルツイン構築とデータの管理方法
(3):3次元空間情報の研究施設「Technology Laboratory」における共通ID「空間ID」と自律移動体の測位技術
(4):G7群馬高崎デジタル・技術大臣会合における空間IDによるドローン運航管理
エンジニアリング編
(1):COVID‐19パンデミック下のオンプレミス環境におけるMLOpsプラクティス
(2):機械学習を用いたデータ分析
(3):AWSで構築したIoTプラットフォームのPoC環境をGCPに移行する方法
(4):テクノロジーの社会実装を高速に検証するPwCの独自手法「Social Implementation Sprint Service」-テクノロジー最前線
(5):自動車業界におけるデジタルコックピットの擬人化とインパクト
(6):成熟度の高いバーチャルリアリティ(VR)システム構築理論の紹介
(7):イノベーションの実現を加速する「BXT Works」とは
(8):Power Platformの承認機能、AI Builderを活用して業務アプリを開発する方
(9):社会課題の解決をもたらす先端テクノロジーとディサビリティ インクルージョンの可能性


