





Responsible AI and model testing: what you need to know


Summary
- AI’s pace of change demands continuous, lifecycle-based testing beyond traditional software development practices.
- Model testing is a trust enabler, helping to confirm AI systems meet quality, resilience and compliance expectations.
- Strong testing culture and clear ownership can improve compliance, reduce risk and enable confident AI adoption.
- Proactive alignment with regulations can help safeguard the business and unlock greater value from AI investments.
This is the eighth in a series of articles focused on how Responsible AI is enhancing risk functions to deliver value and AI innovation.
The rise of generative AI (GenAI) and agentic AI has made many organizations reflect on what they can do to build trust with these new systems. Together with the prominent discussion of AI benchmarks, this has set the stage for the adoption of testing and monitoring practices.
Model testing and monitoring refers to practices for enabling quality, resilience, stability and sustainable decision making with AI systems — and being able to detect when they no longer operate that way or align with the benchmarks we establish.
As an example, imagine an AI-powered system that evaluates candidates for job openings. For the organization to succeed with this system, the people using it need to be confident that it’s reliably offering good recommendations, that it’s not rejecting candidates who might be qualified and that it’s not greenlighting candidates who are not a good fit. Model testing practices can enable consistent evaluation of the AI hiring system to confirm it is performing as expected given different types of candidates, job profiles, geographies or other conditions.
Practically speaking, this means developing processes for testing AI models in several phases of an AI-powered application’s lifecycle:
- Pre-deployment: Validating quality, assessing limitations and verifying stability.
- Post-deployment: Monitoring performance drift, data changes and real-world impacts.
- Compliance: Independent review/attestation aligned with regulatory expectations.
These testing and monitoring phases can be conducted by the team that builds or manages the AI application (sometimes referred to as the “first line”), by an internal yet independent team that is often aligned with the risk function (sometimes referred to as the “second line”), or by a wholly independent party.
How the status quo is changing in model testing and monitoring
Organizations that have not had rigorous, regulatory-driven practices for testing machine learning and statistical models are now realizing the value of consistent model testing and monitoring. However, many don't yet have repeatable ways of assessing the quality, resilience and performance of their AI systems over time and may not have teams ready to do this work.
Even organizations with deep testing experience are struggling with the rise of GenAI and agentic AI, whose technical capabilities and rapid pace of change are creating a need for new testing practices.
Some organizations may believe they have sufficient practices based on their comfort testing software systems prior to deployment. These practices rely upon discrete testing of inputs and outputs (QA testing). AI systems, however, rarely produce the kind of reproducible and expected output that other software systems do.
Here are some of the key differences.
- Software development is fairly linear, while model development is experiment-driven and iterative.
- Software outputs are deterministic, while AI outputs are variable and may be based on relationships in the underlying data that contain biases.
- It’s not easy to align timing of AI model testing with sprints used in software development. Strong AI model governance supports continuous testing aligned with risk profiles for each application.
- After deployment, maintaining accuracy and resilience of AI systems depends on regular monitoring and periodic retesting.
Many organizations have existing cultural, organizational and governance gaps around testing. For example, ownership of monitoring activities is often fragmented, AI development and use are highly decentralized and regulatory frameworks governing AI are uncertain.
In our example of an AI-powered hiring assistant, the application itself may have been developed outside of the usual software development teams and their standardized, controlled practices — perhaps by the HR team itself. The team may not understand the expected level of testing, best practices or the need for ongoing monitoring and testing. While they are likely well versed in employment law, they may not be as aware of the regulatory landscape rapidly developing around AI systems, including those that impact hiring decisions.
If an organization wants to be comfortable with AI models to drive ever more critical and complex decisions, it must invest in standard processes for testing and monitoring those models at all phases of their lifecycle and use. These practices must go above and beyond software testing practices. The organization will need to develop consensus around what it needs to test, who needs to do the testing, when, and how issues are escalated and resolved.
The opportunities for model testing and Responsible AI
Appropriate AI model testing practices don’t just manage risk. Like most Responsible AI practices, good governance drives better return on your investments in model development and AI systems because they can work more reliably, with more predictable, sustainable outcomes. You can also understand better where performance limitations lie, how to make adjustments and where to make human interventions in the most efficient way.
PwC’s Model Edge platform can help organizations operationalize these practices, providing a streamlined environment governance including the definition and documentation of testing requirements. By incorporating a streamlined model management platform into AI workflows, teams can standardize testing, track performance trends and address compliance needs more efficiently.
Good model testing will also give you the confidence to pursue more AI applications and broader transformation goals. AI use cases where you need a high degree of confidence that they’re working appropriately – once elusive – may now seem within organizational risk tolerance.
Key actions to prioritize
- Align on an approach about the model development lifecycle. These may or may not match your existing software development lifecycles. Adapt what is relevant and apply it to developing an organizational consensus around AI model lifecycles. Provide examples of how to test different types of AI systems, including capabilities and agents embedded in third-party applications and stand-alone machine learning-based prediction engines. Also describe an approach to testing and monitoring systems your employees build leveraging generative AI systems, agent frameworks, or other capabilities you provide to drive innovation and productivity.
- Build a culture of testing. Simply telling people that testing is mandatory may not be sufficient. Implementing strong incentives for people to perform the needed tests provides a counterbalance to the “push it into production” mentality that accompanies many AI projects. Enable your teams to think about potential failure points in the AI system and its software environment to proactively design controls. Encourage an inquisitive, iterative spirit of testing.
- Link test guidance with your governance framework. Higher-risk applications should get more rigorous testing. Clarify the obligations of development teams and AI system owners, as well as employees empowered to build on firm AI platforms. Complement that with support from risk and compliance. Understand the organization’s posture on AI risks and design testing and monitoring protocols accordingly.
- Consider what practices are needed to comply with emergent regulations. For example, some regulations require independent bias testing or other specific testing. Collaborate with legal to build these practices into your governance framework, risk assessment processes and model testing practices.
How PwC can help
We help clients to build and evolve their programs relating to AI model testing. We also support our clients by acting as an independent party to test, assess and establish monitoring for AI systems. Whether driven by regulatory need or due to an interest in increasing trust, don’t go it alone.

Trust to the power of Responsible AI
Embrace AI-driven transformation while managing the risk, from strategy through execution.
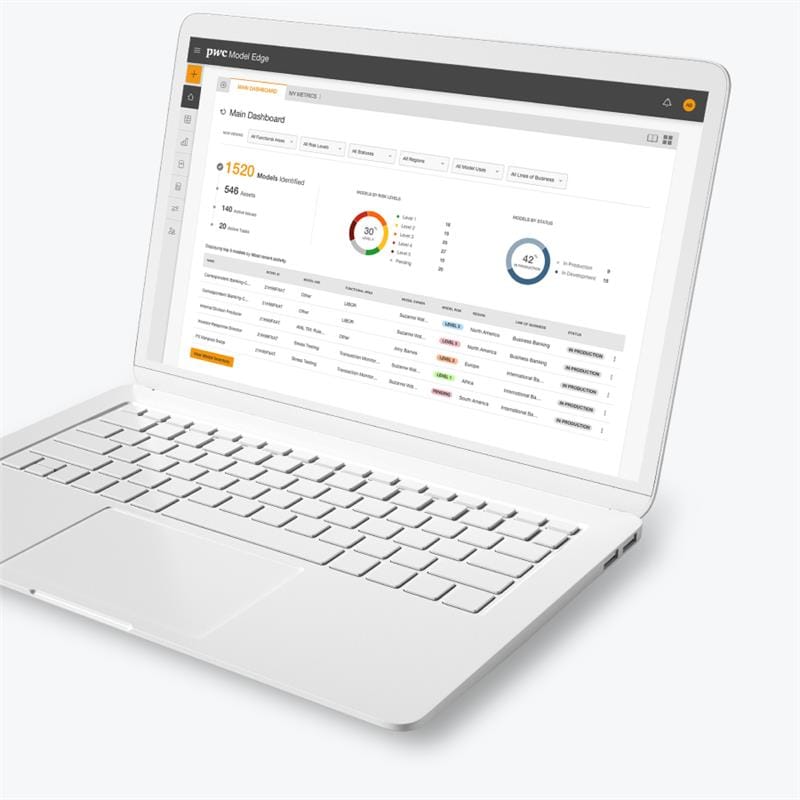
Model Edge
Discover enhanced AI and model governance for effective business transformation.
Next and previous component will go here





