





{{item.videoDuration}}
{{item.title}}
{{item.text}}

{{item.videoDuration}}
{{item.text}}
PwC worked with a leading insurance provider and faced a significant challenge when a costly outage impacted their AWS US-East-1 services. This outage resulted in a disruption to their call center operations, leaving 4,500 agents unable to provide critical services for over 10 hours. To address this issue and improve their resiliency posture, the client worked with PwC to leverage AWS capabilities and implement a multi-region cloud resilience architecture for their critical single-region AWS applications.
The reason for a multi-region cloud resilience architecture on AWS was to give organizations the flexibility and scalability that spans multiple geographic regions, allowing for the distribution of critical applications and data across these regions. This approach confirms that if one region experiences an outage or disruption, the workload can seamlessly failover to another region, reducing downtime and maintaining business continuity.
The benefit of implementing a multi-region resilience architecture is the increased level of resiliency and availability it provides. By distributing applications and data across multiple regions, organizations can mitigate the impact of localized outages or disasters. If one region becomes unavailable, the workload can automatically failover to another region, allowing operations to continue uninterrupted. This approach significantly reduces the risk of prolonged downtime and confirms that critical services can be delivered to customers without disruption.
By leveraging AWS capabilities and working with PwC, the client was able to design and implement a system that could seamlessly failover to another region in the event of a disruption, enabling uninterrupted service delivery to their customers. This approach enhanced their resiliency posture and reduced the impact of future outages, ultimately improving their overall business continuity.
The outage experienced by our client highlighted the need for a strong disaster recovery solution to provide uninterrupted business operations. The company recognized the importance of leveraging AWS services to plan, design, and implement a resilient architecture that could withstand similar incidents in the future. Their primary challenge was to establish a multi-region cloud resilience architecture for critical single-region AWS applications, enabling them to continue operations seamlessly in the event of a disaster.
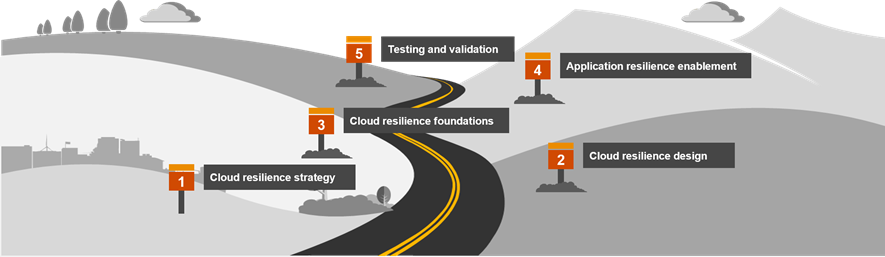
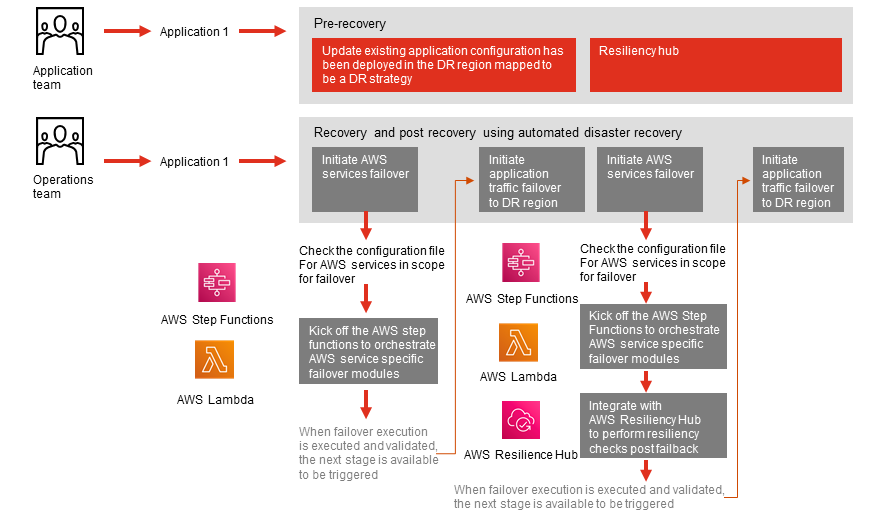
PwC worked across teams to plan, design, and implement a multi-region cloud resilience architecture following our cloud resiliency journey framework. The solution involved several key technical elements to ensure the successful implementation of automated disaster recovery (DR).
Achieving a sustainable AWS resilience organization in an ongoing and long-term journey. The first step is evaluating your resilience capabilities, establishing a baseline and defining a target state. Identifying what processes and services are critical and what it takes to deliver them can help define resilience needs. Strategic and tactical plans should be developed to achieve your target state, taking into account the evolving risk landscape applicable to your organization.
Performing the failover and failback of workloads manually necessitates a dedicated team and thorough preparation to guarantee the proper and successful failover/failback of resources. This procedure is time-consuming. which in turn prolongs the overall recovery time objective (RTO), and it also presents various potential failure points due to its reliance on human intervention.
Automated orchestration of disaster recovery (DR) activities, including the failover of critical services to a healthy AWS region and the failback of AWS services to their original state, enables organizations to quickly and efficiently recover their critical workloads in the event of an incident or for regular DR testing with minimum developer impact.
The implementation of PwC and AWS's automated solution resulted in significant outcomes for the client enhancing their resiliency posture and providing uninterrupted business operations.
We were able to perform an automated disaster recovery operation for critical applications across regions. This allowed them to continue business operations in a secondary region within their target recovery time objective (RTO) and recovery point objective (RPO) of 0 - 4 hours.
The implementation of different disaster recovery approaches enabled the client to generate resilient architecture designs tailored to their specific application requirements and RTO/RPO needs. This flexibility enabled viable resiliency across their digital landscape.
By implementing the disaster recovery orchestration automation, the client successfully performed an automated multi-region failover and failback of critical applications. This capability laid the foundation for replicating the solution across their organization.
PwC's design and implementation efforts identified strategic disaster recovery initiatives for the client. These initiatives provided recommendations for adopting and implementing resilient designs across the organization's Tier 0 and Tier 1 services, further strengthening their resiliency posture.
By working with PwC and leveraging AWS capabilities, the client successfully improved their resiliency posture and automated their disaster recovery processes. The implementation of a multi-region cloud resilience architecture, along with the disaster recovery orchestration automation, provided uninterrupted business operations during a disaster scenario. Our client can now perform multi-region, automated failover and failback of critical applications within their desired RTO/RPO requirements. This case study demonstrates the value of resilient architecture and automated disaster recovery solutions in enhancing business continuity and mitigating the impact of outages.
Explore how PwC and AWS are accelerating breakthrough outcomes.
{{item.text}}
{{item.text}}






